智能体记忆
五层记忆架构:
| 层级 | 类型 | 持久性 | 核心作用 | 类比 |
|---|---|---|---|---|
| L1 | Transformer 上下文 | 会话内 | 当前任务的短期推理、约束保持、工具结果整合 | 工作记忆 |
| L2 | SKILL.md 程序性知识 | 永久 | 告诉模型“某些任务应该怎么做” | 操作手册/SOP |
| L3 | 向量存储索引 | 永久 | 通过语义相似度召回相关历史、文档、片段 | 联想记忆 |
| L4 | Honcho 辩证式用户建模 | 持续进化 | 把交互融合成自然语言用户画像 | 用户理解/心智模型 |
| L5 | FTS5 全文检索 + LLM 摘要 | 永久 | 精准关键词检索、历史归档、长对话压缩 | 档案库/检索目录 |
这五层的本质差异不在“存在哪里”,而在于 记忆对象不同:L1 记当前上下文,L2 记流程,L3 记语义片段,L4 记用户模式,L5 记原文和摘要证据。
大模型为什么需要多层记忆
大模型本身并不天然拥有“长期记忆”。Transformer 的上下文窗口只能处理当前输入范围内的 token,它更像一次推理时的临时工作区,而不是永久数据库。上下文窗口的概念通常和 Transformer 架构相关,用来限定模型一次能处理的信息范围。
所有真正的“记忆系统”通常是工程上额外搭出来的:
- 把当前任务塞进 L1 上下文
- 把长期知识放到外部存储
- 回答前从外部记忆中召回
- 把召回结果重新注入 L1
- 回答后再更新长期记忆
因此,所以“LLM 记忆”,不是模型参数真的每次都被修改,而是
用外部存储 + 检索 + 摘要 + 用户画像 + Prompt 注入,让模型表现得像是长期能记住。
L1: Transformer 上下文,短期推理记忆
L1 是模型当前这一次回答能直接看到的内容,包括:
- 用户本轮问题;
- 当前会话历史;
- 系统指令;
- 工具调用结果;
- 从 L3/L4/L5 召回后塞进来的资料;
- 当前任务的约束、格式、目标
它是 所有记忆最终发挥作用的地方。无论 L2、L3、L4、L5 存得多好,如果没有被注入 L1,模型当前回答时就无法直接使用。
L1 是 推理执行层,不是长期记忆层
L1 不负责长期保存,而负责把其他层召回来的内容临时组织成一次有效推理
L2: SKILL.md,程序性知识记忆
L2 是 程序性记忆,也就是“怎么做某类任务”。
例如:
- 如何处理 PDF;
- 如何生成 PPT;
- 如何编辑 Excel;
- 如何写报告;
- 如何调用某个工具;
- 某类任务的最佳实践;
- 某个组织内部的标准流程
Agent Skills 的设计里,一个 skill 通常是一个目录,里面包含 SKILL.md,用于描述技能名称、触发条件、操作说明、脚本和资源;Anthropic 文档也明确提到,SKILL.md 主体可以包含工作流、最佳实践和操作指导等程序性知识。
普通 Prompt 是一次性的。SKILL.md 是可复用的。比如你每次让模型处理 PPT,不需要每次都告诉它:
- 页面比例怎么处理;
- 字体如何控制;
- 母版怎么复用;
- 图片怎么压缩;
- 如何保证可编辑;
- 最终如何导出。
这些都可以沉淀到 L2。
L2 的核心是:
把知识沉淀成 SOP,让 Agent 不用每次重新探索,L2 不是 “用户记忆”,而是 “能力记忆”。L2 需要版本管理、来源校验、权限控制和定期评审。
L3: 向量存储索引,语义记忆
L3 是典型的 RAG / 向量数据库记忆
它会把历史对话、文档、知识片段切块,然后转成 embedding 向量,存到向量库里。回答前再把用户问题转成向量,去找语义上最接近的内容。Pinecone 文档把语义搜索描述为在稠密向量索引中查找与查询在意义和上下文上最相似的记录;Qdrant 文档也把近邻向量搜索作为相似性搜索的核心。
L3 解决的是:
- 用户没有说原词,但语义相关;
- 历史资料很多,无法全部塞进 L1;
- 需要跨会话找相似任务;
- 需要从大量文档中找到相关片段。
L3 需要配合:
- chunking;
- metadata;
- rerank;
- 时间过滤;
- 来源权重;
- hybrid search;
- 去重;
- 证据引用
L4: Honcho 辩证式用户建模,持续进化画像
L4 是这套架构里最“高级”的部分。
它不是简单保存聊天记录,而是把历史交互融合成用户画像。
Honcho 官方文档将其定位为面向 Agent 的记忆与用户建模基础设施,支持自然语言查询、自动上下文管理、多 Agent 支持等能力。 Honcho 的架构文档还提到 Dialectic API 可以让开发者通过 /chat 端点与 Honcho 讨论某个 Peer,从而获得关于用户心理、偏好、行为模式的洞察,并用于个性化、模型引导和 Prompt 注入。
“正-反-合循环”非常关键。
它不是一次性贴标签,而是动态修正。
正:形成假设
例如系统观察到:
用户经常让 AI 帮忙写方案、PPT、流程图、技术分析。
初步画像可能是:
用户偏好结构化、业务落地型输出。
反:寻找矛盾和补充
但系统继续观察:
用户也经常做海报、壁纸、提示词、微信文案、旅游攻略。
于是它会修正:
用户不是单纯技术型,也重视审美、表达、实用传播。
合:融合成更稳定画像
最后形成综合画像:
用户经常在工作场景中使用 AI,需求横跨方案、PPT、流程图、HR 通知、宣传物料和视觉提示词。回答应偏实用、结构化、可直接复制,同时兼顾表达效果和视觉呈现。
这就是 “合”。
L3 存的是“相关片段”;L4 存的是“对用户的理解”。
L4 让 Agent 从“查资料”升级为“懂用户”。
它可以影响:
- 回答深度;
- 语言风格;
- 输出格式;
- 是否给表格;
- 是否可复制版本;
- 是否补充技术路径;
- 是否避免过度理论化;
- 是否主动联想到用户当前项目
L4 可以给用户建模带来个性化。
L5: FTS5 全文检索 + LLM 摘要,精确归档记忆
L5 是全文检索和摘要压缩层。
FTS5 是 SQLite 的全文检索扩展,官方文档将其描述为 SQLite 的虚拟表模块,用于在大量文档中高效搜索包含某些词项的文本。
它和 L3 最大的区别是:
- L3: 语义相似;
- L5: 关键词 / 短语 / 原文匹配
适用的场景:精确查找内容
- 某个命令;
- 某个版本;
- 某个人名;
- 某个项目名;
- 某个标题;
- 某段原文;
- 某个日期;
- 某个术语。
例如用户问:
我之前那个 vLLM 关闭思考过程的 curl 命令是什么
L3 可能召回一堆 “vLLM” 推理相关内容。
但 L5 可以直接搜:
1 | vllm curl max_tokens temperature 思考过程 |
然后找到原文。
LLM 摘要可以把长对话压缩成:
- 会话摘要;
- 项目摘要;
- 决策摘要;
- 待办摘要;
- 用户偏好摘要;
- 文件摘要。
例如一段很长的项目讨论,可以压缩成:
用户正在做医院廉洁风险平台,当前已有药学和耗材数据,缺少样本外送数据;短期目标包括月度报告模板优化、样本外送合规预警、临采流程智能化、预警归因分析增强。
这样下次检索时不用拉取完整历史。
L5 相较于 L4 的核心优势是 可追溯、可解释、精确匹配。
它能回答:
“我到底说过什么?”
而 L4 更像回答:
“你长期看起来是什么偏好?”
L5 是证据层;L4 是画像层。
L5 的缺点:
- 不擅长语义扩展;
- 用户换一种说法就可能搜索不到;
- 摘要可能丢细节;
- 原文多时需要排序和去重;
- 关键词分词、中文检索、同义词处理会影响召回。
所以 L5 最好和 L3 组合成 Hybrid Search。
五层之间的协同关系
可以把五层记忆理解成这条链路:
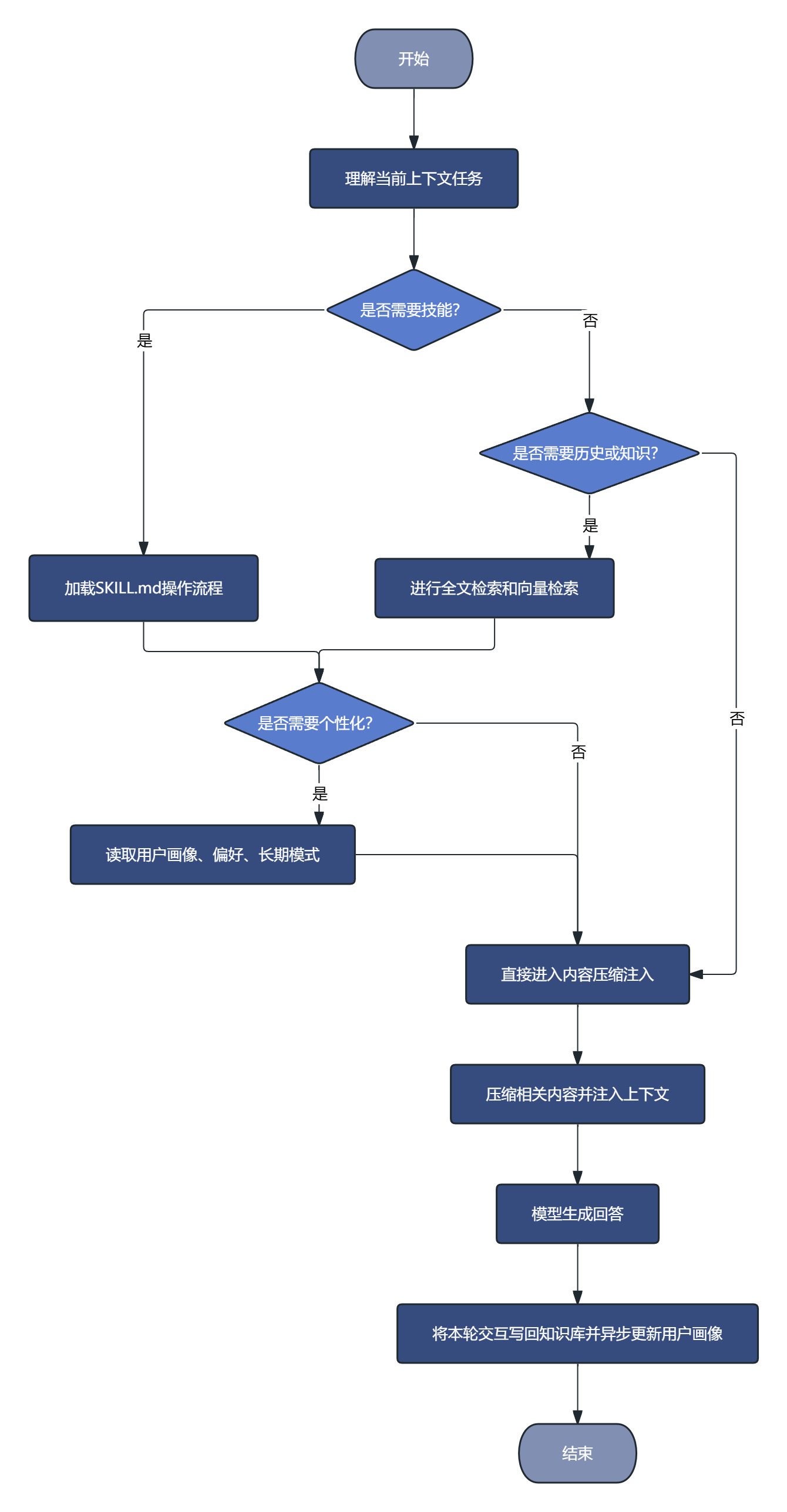
这就是完整的大模型记忆闭环。
五层的权威性排序
实际工程里,最容易出问题的是 记忆冲突。
比如:
- L4 记得用户偏好“简洁”;
- 但当前用户说“请帮我深度剖析”;
- 那应该听谁?
推荐优先级:
当前用户显式指令 > 当前上传文件/工具结果 > L2 技能规则 > L5 原文证据 > L3 语义召回 > L4 用户画像
五层分别回答什么问题
| 层级 | 它回答的问题 |
|---|---|
| L1 | “我现在正在处理什么?” |
| L2 | “这类任务应该怎么做?” |
| L3 | “过去有哪些语义相关内容?” |
| L4 | “这个用户长期是什么风格、偏好和目标?” |
| L5 | “原文里到底出现过什么?” |
这五个问题结合起来,才构成完整记忆

